2024.08.09
Mixture-of-Agents Enhances Large Language ModelCapabilities論文を日本語訳してみた
まずは要約です。
論文の題名と著者名、発行年
- 題名: Mixture-of-Agents Enhances Large Language Model Capabilities
- 著者: Junlin Wang (Duke University), Jue Wang, Ben Athiwaratkun, Ce Zhang, James Zou (Together AI, University of Chicago, Stanford University)
- 発行年: 2024年(プレプリント)
どんなもの?
この論文では、複数の大規模言語モデル(LLM)の集団的な強みを活用するための新しいアプローチとして、**ミクスチャー・オブ・エージェンツ(MoA)**という手法を提案しています。この手法では、複数のLLMを層ごとに配置し、各層のエージェントが前層の出力を利用してより良い応答を生成します。この手法により、AlpacaEval 2.0やMT-Benchなどのベンチマークで最先端の性能を達成しました。
先行研究と比べてどこがすごい?
従来のLLMの限界として、モデルサイズや訓練データの制約がありましたが、この論文のアプローチは、異なるLLMの強みを活かしながら、それぞれの欠点を補完することで、より高品質な出力を生成することに成功しています。特に、異なるモデルの出力を組み合わせる「協調性」を示し、これを最大限に活用した点が革新的です。
技術や手法のキモはどこ?
**ミクスチャー・オブ・エージェンツ(MoA)**の手法の核は、複数のLLMを層状に配置し、各エージェントが前層の出力を活用して応答を生成することにあります。これにより、各層の出力が次の層でさらに洗練され、最終的に高品質な応答が得られます。特に、モデルの選択基準として、性能指標と出力の多様性が重視されています。
どうやって有効だと検証した?
AlpacaEval 2.0、MT-Bench、FLASKなどのベンチマークを用いて、提案されたMoA手法の有効性を検証しました。その結果、AlpacaEval 2.0で65.1%、MT-Benchで9.25、FLASKでの評価においても優れた結果を達成し、既存の最先端モデルを上回る性能を示しました。
議論はある?
論文では、MoAの効果を最大化するためのモデルの選択と配置について議論されています。また、提案手法の制限として、応答生成の速度(初回の応答までの時間)が課題として挙げられており、今後の研究で改善が期待されています。
次に読むべき論文は?
- Mixture-of-Experts (MoE)の手法について理解を深めるために、Shazeer et al. (2017)の研究を読むことが推奨されます。
- また、協調性を持つLLMの応答生成の改善についてさらに掘り下げるため、Chain-of-ThoughtやTree-of-Thoughtに関する研究も参考になります。
以下~が本文です。
Mixture-of-Agentsが大規模言語モデルの能力を強化
著者:
- Junlin Wang (デューク大学, Together AI)
- Jue Wang (Together AI)
- Ben Athiwaratkun (Together AI)
- Ce Zhang (シカゴ大学, Together AI)
- James Zou (スタンフォード大学, Together AI)
要旨: 最近の大規模言語モデル(LLM)の進展は、自然言語の理解と生成タスクにおいて大きな能力を示しています。LLMの数が増加する中で、複数のLLMの集団的な専門知識を活用する方法は、非常に魅力的な研究分野です。この目的に向けて、私たちは新しいアプローチを提案し、複数のLLMの集団的な強みを活用する**Mixture-of-Agents (MoA)**という手法を導入しました。このアプローチでは、各層に複数のLLMエージェントを配置する層状のMoAアーキテクチャを構築します。各エージェントは、前の層のエージェントのすべての出力を補助情報として使用し、応答を生成します。MoAモデルは、AlpacaEval 2.0、MT-Bench、およびFLASKで最先端のパフォーマンスを達成し、GPT-4 Omniを超えました。例えば、私たちのMoAは、オープンソースのLLMのみを使用してAlpacaEval 2.0で65.1%のスコアを達成し、GPT-4 Omniの57.5%を大きく上回っています。
1. はじめに
大規模言語モデル(LLM)は、近年の自然言語理解と生成の分野で大きな進歩を遂げました。これらのモデルは膨大なデータで事前訓練され、その後、人間の好みに合わせて調整され、役立つ一貫した出力を生成します。しかし、LLMの多様性とその成果にもかかわらず、モデルサイズや訓練データに固有の制約があります。これらのモデルをさらにスケールアップすることは非常に高価であり、何兆ものトークンに対して広範な再訓練を必要とします。
同時に、異なるLLMは異なるタスクにおいて独自の強みを持ち、特定の分野に特化しています。例えば、あるモデルは複雑な指示のフォローが得意である一方、別のモデルはコード生成に向いているかもしれません。このようなLLM間の多様なスキルセットは、「複数のLLMの集団的な専門知識を活用して、より能力が高く堅牢なモデルを作成できるか」という興味深い問いを生み出します。
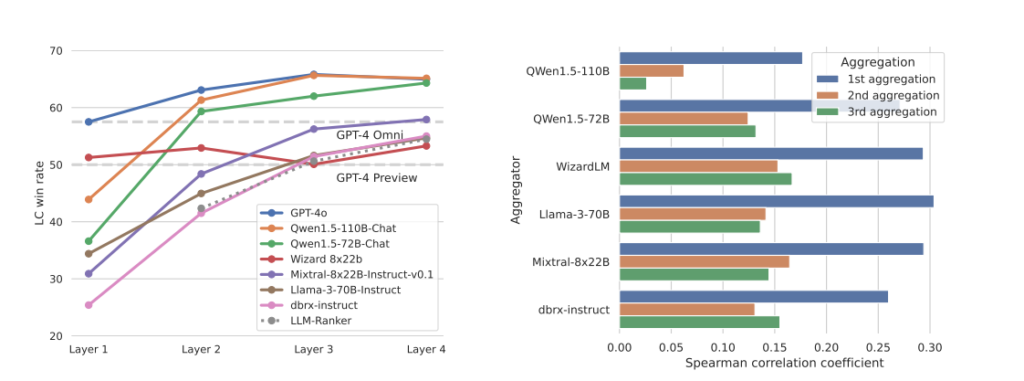
私たちの答えは「はい」です。私たちは、LLMの協調性という固有の現象を確認しました。これは、他のモデルの出力を提供された場合、たとえそれらのモデルが自らよりも劣っていたとしても、LLMがより良い応答を生成する傾向があることを意味します。図1は、6つの人気のLLMについて、AlpacaEval 2.0ベンチマークでのLC勝率を示しています。
図1
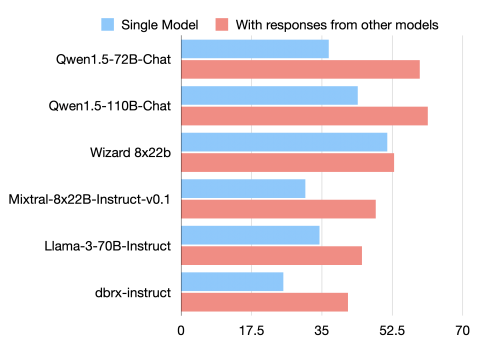
図2
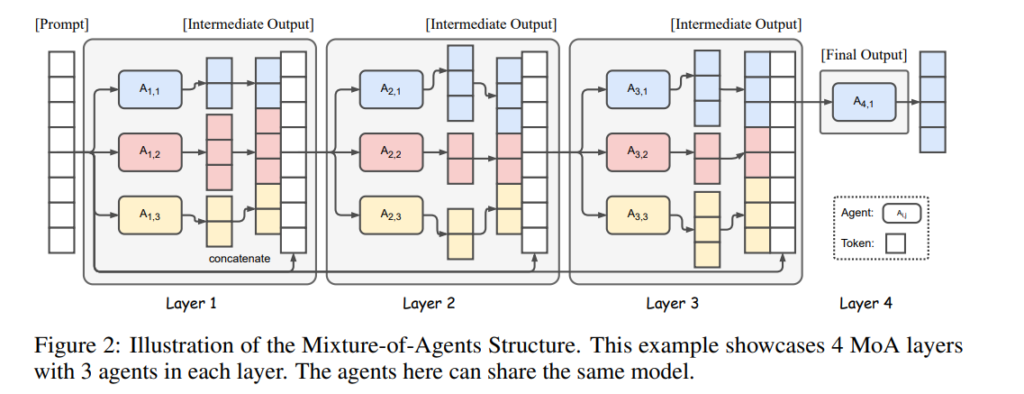
図1: 他のモデルからの応答を提供されたときにAlpacaEval 2.0 LC勝率が向上する。
これらのモデルが独立して生成した応答を提供されたとき、それらのLC勝率は大幅に向上しました。これは、LLM間で協調性が広く見られる現象であることを示しています。注目すべきことに、この改善は、他のモデルが生成した補助的な応答の品質が、個別のLLMが独立して生成するものよりも低い場合でも発生します。
この発見に基づいて、この論文では、複数のLLMを活用して生成品質を逐次的に向上させる**Mixture-of-Agents (MoA)**手法を紹介します。MoAの構造は図2に示されています。最初に、最初の層にあるLLM(エージェントA1,1, A1,2, … A1,n)は、与えられたプロンプトに対して独立して応答を生成します。これらの応答は次の層のエージェントA2,1, … A2,nに提供され、さらに洗練されます。この逐次的な洗練プロセスは、より堅牢で包括的な応答が得られるまで数回繰り返されます。
モデル間の効果的な協力を確保し、全体的な応答品質を向上させるためには、各MoA層に適したLLMの慎重な選択が重要です。この選択プロセスは主に2つの基準によって導かれます:(a) パフォーマンス指標: 層iのモデルの平均勝率は、層i+1に含めるべきかどうかを決定する際に重要な役割を果たします。したがって、実証されたパフォーマンス指標に基づいてモデルを選択することが、より高品質な出力を確保するために重要です。(b) 多様性の考慮: モデル出力の多様性も重要です。後のセクション3.3で示すように、異質なモデルによって生成された応答は、同じモデルによって生成された応答よりもはるかに大きな貢献をします。これらの基準、すなわちパフォーマンスと多様性を活用することで、MoAは個々のモデルの欠点を軽減し、協力的な統合によって全体的な応答品質を向上させることを目指しています。
私たちは、AlpacaEval 2.0、MT-Bench、FLASKベンチマークを用いて、さまざまな次元での応答品質を評価する包括的な評価を行いました。結果は、提案手法が大幅な改善をもたらし、AlpacaEval 2.0で65.8%という新たな最先端の勝率を達成したことを示しています。これは、以前の最良のスコアであるGPT-4 Omniの57.5%を上回るものです。
この研究の貢献は以下の通りです:
- 新しいフレームワーク: 複数のLLMの強みを活用して、推論および言語生成能力を向上させることを目的としたMixture-of-Agentsフレームワークを提案しました。
- LLMの協調性の発見: 他のモデルの出力にアクセスすることで、モデルがより高品質な応答を生成する傾向があるという、LLM間の固有の協調性を強調しました。
- 最先端のLLMパフォーマンス: AlpacaEval 2.0、MT-Bench、FLASKなどの複数の高競争力のあるベンチマークを使用した広範な実験を実施し、私たちのMoAフレームワークがこれらのベンチマークで最先端のパフォーマンスを達成しました。
2 Mixture-of-Agents手法
このセクションでは、複数のモデルを活用して性能を向上させるための提案手法を紹介します。まず、LLMが協調性を持ち、他のモデルの出力に基づいて応答の質を向上させることができることを示します。その後、Mixture-of-Agents手法を導入し、その設計の影響について論じます。
2.1 LLMの協調性
まず、LLMが他のモデルの出力を参照することでより高品質な応答を生成できる協調性を示します。導入と図1で示したように、現在利用可能な多くのLLMはこの協調能力を持っています。
複数のLLMの協力から最大の利益を引き出すための重要な方法は、協力の様々な側面で異なるモデルがどのように優れているかを特定することです。協力プロセス中に、LLMを以下の2つの役割に分類することができます:
- 提案者(Proposer): 他のモデルが使用する参考応答を生成するのに優れています。優れた提案者は、必ずしも自ら高スコアの応答を生成するわけではありませんが、より多くのコンテキストと多様な視点を提供し、最終的に集約者が使用する際により良い応答に貢献します。
- 集約者(Aggregator): 他のモデルからの応答を単一の高品質な出力に統合するのに優れています。効果的な集約者は、自らの品質を維持しつつ、他のモデルからの入力が自分の品質よりも低くても、それをうまく統合します。
セクション3.3では、集約者と提案者の役割を実証的に検証します。具体的には、多くのLLMが集約者および提案者の両方としての能力を持っている一方で、一部のモデルは特定の役割において優れた専門性を示すことが分かりました。例えば、GPT-4o、Qwen1.5、LLaMA-3は、支援と集約の両方で効果的な多用途モデルとして登場しました。一方、WizardLMは提案者モデルとして優れた性能を発揮しましたが、他のモデルの応答を集約する際にはその有効性を維持するのに苦労しました。
集約者が他のモデルの出力を基にしてより高品質な応答を生成できることを考慮すると、この協力の可能性をさらに高めるために、追加の集約者を導入することを提案します。直感的なアイデアとしては、複数の集約者を使用してまずはより良い応答を集約し、それを再度集約することが挙げられます。これにより、より多くの集約者をプロセスに組み込むことで、複数のモデルの強みを活用して応答を反復的に合成および洗練し、最終的に優れた結果を得ることができます。これが、提案するMixture-of-Agentsの設計に繋がります。
2.2 Mixture-of-Agents
MoAの構造は図2に示されています。MoAにはl層があり、各層iはn個のLLM(Ai,1, Ai,2, …, Ai,n)で構成されています。LLMは同じ層内または異なる層間で再利用できます。多くのLLMが同じ層に存在する場合、この構成は、モデルが複数の可能な異なる出力を生成する設定(温度サンプリングの確率性による)に対応します。この設定を単一提案者と呼びます。この場合、一部のモデルだけが活性化されます。
ここで、各LLM Ai,jは入力テキストを処理し、その続きのテキストを生成します。この方法は微調整を必要とせず、LLMのプロンプトと生成インターフェースだけを利用します。形式的には、入力プロンプトx1が与えられたとき、i番目のMoA層の出力yiは次のように表されます:
yi=⊕nj=1[Ai,j(xi)]+x1,xi+1=yiyi = ⊕n_{j=1}[Ai,j(xi)] + x1, xi+1 = yiyi=⊕nj=1[Ai,j(xi)]+x1,xi+1=yi
ここで、+はテキストの連結を意味し、⊕はこれらのモデル出力にAggregate-and-Synthesizeプロンプト(表1)を適用することを意味します。
表1: 他のモデルからの応答を統合するためのAggregate-and-Synthesizeプロンプト
あなたには、さまざまなオープンソースモデルが提供する最新のユーザークエリへの応答セットが提供されています。あなたのタスクは、これらの応答を単一の高品質な応答に統合することです。これらの応答に含まれる情報が偏っていたり、誤っている可能性があることを認識しながら、提供された答えを単に複製するのではなく、洗練され、正確で包括的な回答を提供してください。応答は、構造化され、一貫性があり、正確性と信頼性の最高基準に従うものである必要があります。
2.3 Mixture-of-Expertsとの類似性
Mixture-of-Experts(MoE)は、機械学習において複数の専門ネットワークが異なるスキルセットを持つ手法としてよく知られています。MoEアプローチは、その多様なモデル能力を活用して、複雑な問題解決タスクにおいて大きな成功を収めています。私たちのMoA手法は、この手法からインスピレーションを得ています。
典型的なMoEの設計は、MoE層と呼ばれる層のスタックで構成されます。各層にはn個の専門ネットワークがあり、ゲーティングネットワークと残差接続が含まれ、勾配の流れを改善します。形式的には、層iにおけるこの設計は次のように表されます:
yi=∑j=1nGi,j(xi)Ei,j(xi)+xiyi = \sum_{j=1}^{n} Gi,j(xi)Ei,j(xi) + xiyi=∑j=1nGi,j(xi)Ei,j(xi)+xi
ここで、Gi,jは専門ネットワークjに対応するゲーティングネットワークの出力を表し、Ei,jは専門ネットワークjが計算する関数を示します。複数の専門家を活用することで、モデルは異なるスキルセットを学び、タスクのさまざまな側面に焦点を当てることができます。
高レベルの視点から、私たちの提案するMoAフレームワークは、モデルレベルで操作することによりMoEの概念を拡張しています。具体的には、MoAアプローチはLLMを活用し、内部のアクティベーションや重みを変更するのではなく、完全にプロンプトインターフェースを介して操作します。これは、MoEのように単一のモデル内の専門サブネットワークを持つ代わりに、異なる層にわたって複数の完全なLLMを利用することを意味します。さらに、このアプローチでは、ゲーティングネットワークと専門ネットワークの役割をLLMに統合しており、LLMの内在する能力により、プロンプトを解釈し、一貫した出力を生成することで、外部の調整メカニズムを必要とせずに入力を効果的に正則化することが可能です。
さらに、この方法は、市販のモデルに備わっているプロンプト機能のみに依存しているため、以下の利点があります:
- 微調整に関連する計算オーバーヘッドを排除できる。
- 柔軟性とスケーラビリティがある:私たちの方法は、最新のLLMにサイズやアーキテクチャに関係なく適用可能です。
3 評価
このセクションでは、提案されたMixture-of-Agents(MoA)手法の包括的な評価結果を示します。私たちの発見は以下の通りです:
- AlpacaEval 2.0、MT-Bench、FLASKベンチマークで大幅な改善を達成: 特にオープンソースモデルのみを使用した場合でも、AlpacaEval 2.0およびFLASKでGPT-4oを上回る結果を得ました。
- MoAの内部メカニズムの理解を深めるための広範な実験を実施: MoAの内部メカニズムの理解を深めるために広範な実験を行いました。
- コスト分析によるMoAの効率性の検証: MoAのいくつかの実装が、GPT-4 Turboと同等の性能を達成しながら、コスト効率が2倍であることを示す詳細なコスト分析を実施しました。
3.1 設定
ベンチマーク: 主にAlpacaEval 2.0(Dubois et al., 2024)でモデルを評価しました。これは、LLMの人間の好みに対する整合性を評価するための主要なベンチマークです。このベンチマークには、実際の使用ケースを代表する805の指示が含まれています。各モデルの応答はGPT-4(gpt-4-1106-preview)の応答と直接比較され、GPT-4ベースの評価者が評価されたモデルの応答を好む可能性を判断します。公平性を確保するために、長さに依存しない長さ制御(LC)勝率が使用され、長さバイアスが効果的に中和されています。
また、MT-Bench(Zheng et al., 2023)およびFLASK(Ye et al., 2023)でも評価を行いました。MT-Benchでは、GPT-4がモデルの応答を評価し、スコアを与えます。一方、FLASKは12のスキル固有のスコアでより詳細な評価を提供します。
モデル: 私たちの研究では、競争力のある性能を達成するためにオープンソースモデルのみを使用してデフォルトのMoAを構築しました。使用したモデルには、Qwen1.5-110B-Chat(Bai et al., 2023)、Qwen1.5-72B-Chat、WizardLM-8x22B(Xu et al., 2023a)、LLaMA-3-70B-Instruct(Touvron et al., 2023b)、Mixtral-8x22B-v0.1(Jiang et al., 2024)、dbrx-instruct(The Mosaic Research Team, 2024)が含まれます。3つのMoA層を構築し、各MoA層で同じセットのモデルを使用しました。最終層の集約者としてQwen1.5-110B-Chatを使用しました。また、最終MoA層の集約者としてGPT-4oを使用することで高品質な出力を優先するMoA w/ GPT-4oというバリアントも開発しました。もう一つのバリアントであるMoA-Liteは、費用対効果に重点を置いています。これは提案者として同じモデルセットを使用しますが、MoA層を2つに減らし、集約者としてQwen1.5-72B-Chatを採用しています。これにより、GPT-4oよりも費用対効果が高く、AlpacaEval 2.0で1.8%の品質向上を実現しました。私たちは、研究で使用したすべてのモデルのライセンス条件を厳格に遵守しています。オープンソースモデルについては、Together Inference Endpointを通じてすべての推論を行いました。
6ページ目の日本語訳を以下に示します。
3.2 ベンチマーク結果
このセクションでは、AlpacaEval 2.0、MT-Bench、FLASKの3つの標準ベンチマークにおける評価結果を示します。これらのベンチマークは、私たちのアプローチのパフォーマンスを総合的に評価し、最先端のLLMと比較するために選ばれました。
AlpacaEval 2.0
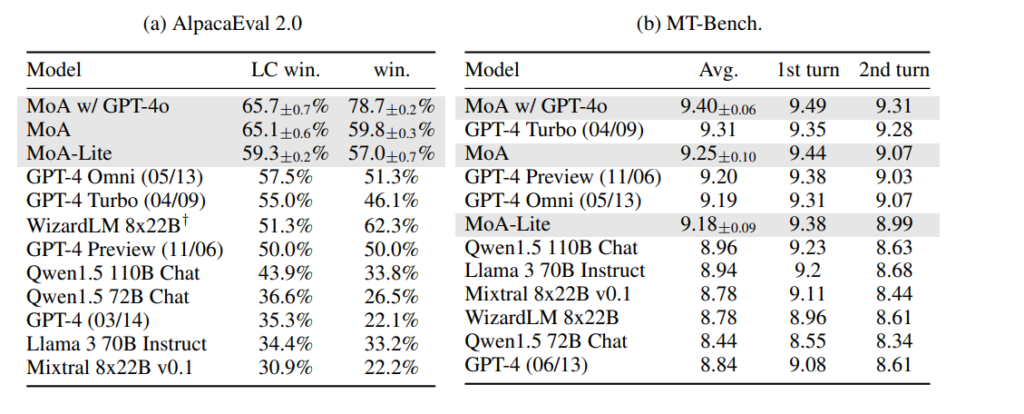
私たちは、GPT-4やその他の最先端のオープンソースモデルと比較を行いました。詳細な結果は表2aに示されており、私たちのMoA手法がAlpacaEval 2.0リーダーボードでトップの位置を獲得し、以前のトップモデルであるGPT-4oを8.2%上回る絶対的な改善を達成しました。特に注目すべきは、オープンソースモデルのみを使用してGPT-4oを上回り、57.5%(GPT-4o)から65.1%(MoA)へと7.6%の絶対的な改善を達成した点です。また、MoA-Lite設定では、層の数を減らし費用対効果を高めています。この軽量化されたアプローチでも、57.5%(GPT-4o)から59.3%(MoA-Lite)へと1.8%の改善を達成しており、オープンソースモデルの能力を限られた計算資源で最大限に活用する私たちの手法の効果をさらに示しています。
MT-Bench
MT-Benchでの改善は個々のモデルに対しては比較的わずかですが、これは現在のモデルがすでにこのベンチマークで非常に高いパフォーマンスを発揮しているためです。単一のモデルでも10点満点中9点以上を獲得できるため、このベンチマークでの改善はわずかなものにとどまっています。それでもなお、私たちのアプローチはリーダーボードのトップの位置を確保しています。これは、すでに最適化されたベンチマークでも、私たちの手法がさらなる向上を実現できることを示しており、リーダーシップを維持しています。
FLASK
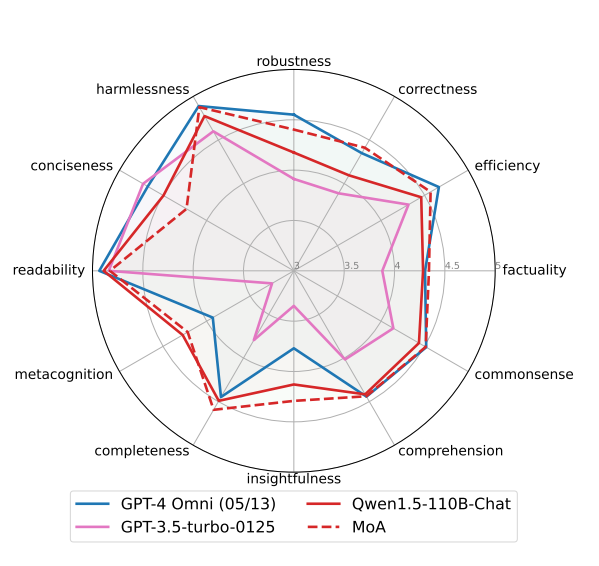
FLASKでは、モデルの詳細な評価が行われます。これらの指標の中で、MoAは特定の重要な側面で顕著な改善を示しています。具体的には、頑健性、正確性、効率性、事実性、常識、洞察力、完全性において、集約者であるQwen-110B-Chatの単一モデルスコアを上回っています。さらに、MoAはGPT-4 Omniに対しても、正確性、事実性、洞察力、完全性、メタ認知の面で優れた性能を示しています。ただし、MoAがあまりうまくいかなかった指標として簡潔さが挙げられます。モデルはわずかに冗長な出力を生成する傾向がありました。
図3
3.3 Mixture-of-Agentsがうまく機能する理由
このサブセクションでは、Mixture-of-Agentsの内部メカニズムを理解するために実施した実験について説明し、重要な洞察をまとめます。
Mixture-of-AgentsはLLMランカーを大きく上回る
まず、Mixture-of-AgentsとLLMベースのランカーを比較しました。LLMランカーは、提案者が生成した回答の中から集約者モデルが1つを選ぶ方式を取ります。結果は図4に示されており、MoAアプローチがLLMランカーベースラインを大きく上回ることが確認されました。MoAがランク付けアプローチを上回る事実は、集約者が単に提案者によって生成された応答の一つを選んでいるのではなく、すべての提案された生成物に対して高度な集約を行っていることを示唆しています。
MoAは最良の提案応答を組み込む傾向がある
また、集約者の応答と提案者の応答をBLEU(Papineni et al., 2002)などの類似性スコアを使って比較しました。このスコアはn-gramの重複を反映します。各サンプル内で、n個の提案応答に対して、n個の類似スコアとGPT-4ベースの評価者によって決定されたn個の好みスコアとの間のスピアマン順位相関係数を計算しました。図4の結果は、勝率とBLEUスコアとの間に正の相関があることを確認しています。
図4
さらに、Appendix Aでは、Levenshtein類似度やTF-IDFを用いた場合のテキスト類似度でも、好みのスコアと正の相関があることを示しています。
図4: (a) AlpacaEval 2.0での6モデルMixture-of-Agents設定における異なる集約者のLC勝率。すべての曲線は同じ6つの提案者エージェントを使用しており、最終集約者の選択だけが異なります。LLMランカーは、Appendixの表5のプロンプト形式でQwen1.5-110B-Chatモデルを使用しています。GPT-4oモデルは、評価目的で出力を集約するためにのみ使用され、次の層に向けた提案者としては機能しません。(b) 提案された出力の勝率とBLEUスコア(3-gram、4-gram、5-gramメトリクスを使用)のスピアマン相関。
表3: AlpacaEval 2.0における提案者モデルの数の影響を示す。nはMoA層内のエージェントの数、または単一提案者設定での提案出力の数を指します。すべての設定においてQwen1.5-110B-Chatを集約者とし、2つのMoA層を使用します。
| 設定 | 複数提案者 | 単一提案者 |
|---|---|---|
| n = 6 | 61.3% | 56.7% |
| n = 3 | 58.0% | 56.1% |
| n = 2 | 58.8% | 54.5% |
| n = 1 | 47.8% | 47.8% |
表4: 提案者と集約者として機能する異なるモデルの影響。異なる集約者を評価する際には、6つのモデルすべてが提案者として機能します。提案者を評価する際には、Qwen1.5-110B-Chatが集約者として機能します。この表では2つのMoA層を使用しています。
| モデル | 集約者としての性能 | 提案者としての性能 |
|---|---|---|
| Qwen1.5-110B-Chat | 61.3% | 56.7% |
| Qwen1.5-72B-Chat | 59.3% | 53.3% |
| LLaMA-3-70b-Instruct | 45.0% | 60.6% |
| WizardLM 8x22B | 52.9% | 63.8% |
| Mixtral-8x22B-Instruct | 48.4% | 54.8% |
| dbrx-instruct | 41.5% | 55.1% |
モデルの多様性と提案者の数の影響
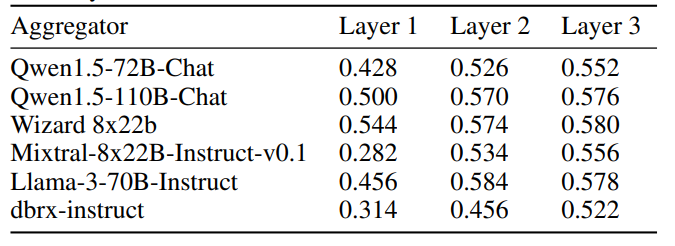
提案の数が最終出力の品質にどのように影響するかを、各層における提案者の数nを変化させて分析しました。結果は表3に示されており、スコアはnの増加に伴い一貫して向上し、補助情報を多く持つことの利点が反映されています。さらに、異なるLLMを提案者として使用することの影響も定量化しました。各nについて、「単一提案者」設定(温度0.7で同じLLMによって生成されたn個の応答)と「複数提案者」設定(各応答が異なるLLMによって生成される)を比較しました。全体として、複数の異なるLLMエージェントを各MoA層に配置することで、より良い結果が得られました。MoAの幅をさらに広げることは、今後の研究で有望な方向性であることが示唆されます。
Mixture-of-Agentエコシステムにおけるモデルの専門性
私たちは、特定の役割で優れたパフォーマンスを発揮するモデルを特定するための実験も行いました。具体的には、表4に示されているように、GPT-4o、Qwen、LLaMA-3が支援と集約の両方で効果的な多用途モデルとして登場しました。一方で、WizardLMは提案者モデルとして優れた性能を発揮しましたが、他のモデルの応答を集約する際にはその有効性を維持するのに苦労しました。
3.4 予算とトークン分析
予算、トークン使用量、およびLC勝率の関係を理解するために、予算とトークンの分析を行いました。図5aおよび図5bはこれらの関係を示しています。
図5
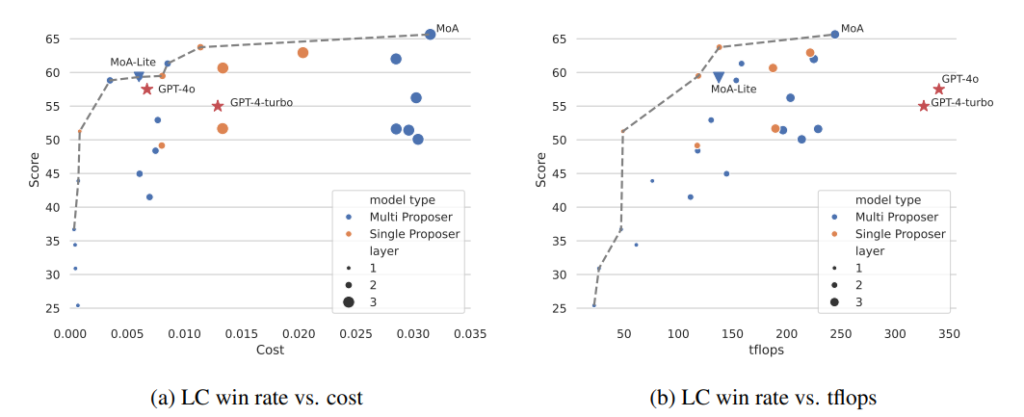
図5: (a) コストとLC勝率のトレードオフ (b) テラフロップス数とLC勝率のトレードオフ
(a) LC勝率と平均推論コストの関係を示すグラフです。コストはAPIプロバイダーのWebサイトから入手した価格情報に基づいて計算されました。この分析により、高性能を達成しながらも過剰なコストをかけずにすむコスト効率の良いモデルを特定できます。グラフは、一定のコストで高いスコアを得ることができるモデルを示すパレートフロンティアを明らかにしています。MoAアプローチは、このパレートフロンティアに位置しており、同じLC勝率を達成するためのコストがGPT-4 TurboやGPT-4oよりも低く、コスト効率が優れていることが示されています。
(b) LC勝率とテラフロップス数(tflops)の関係を示すグラフです。ここでは、tflops数を遅延のプロキシとして使用しています。この分析は、異なるモデルがその予算をどのように管理しつつ、パフォーマンスレベルを維持または向上させているかを理解するのに重要です。コスト効率の分析と同様に、ここでもパレートフロンティアが観察されます。このフロンティア上のモデルは、計算リソースを効果的に利用してLC勝率を最大化しています。
コスト効率
図5aでは、AlpacaEval 2.0ベンチマークの各インスタンスに対する平均推論コストに対するLC勝率をプロットしています。コストはAPIプロバイダーのWebサイトから入手した価格情報に基づいて計算されました。このチャートは、コストとパフォーマンスのバランスを考慮した際に、最適なモデルを特定するのに役立ちます。特に、品質を重視する場合、MoAが最も優れた構成です。しかし、品質とコストのバランスを重視する場合、MoA-LiteはGPT-4oと同等のコストでより高い品質を達成できます。特に、GPT-4 Turboよりも約4%優れた性能を示し、コスト効率も2倍以上です。
テラフロップス消費
図5bは、LC勝率とテラフロップス数の関係を示しています。ここでは、tflops数を遅延のプロキシとして使用しています。この分析は、異なるモデルが予算をどのように管理しつつ、パフォーマンスを維持または向上させているかを理解するのに重要です。コスト効率の分析と同様に、ここでもパレートフロンティアが観察されます。このフロンティア上にあるモデルは、計算リソースを効果的に利用してLC勝率を最大化しています。
4 関連研究
4.1 LLMの推論
LLMの生成品質を向上させるために、最近の研究ではプロンプトエンジニアリングを通じてさまざまな下流タスクの最適化が大きく進展しています。Chain of Thought (CoT) 推論技術は、各ステップが前のステップに基づいて構築される線形の問題解決アプローチを代表しています。Fu et al. (2022)は、CoTを複数ステップの推論タスクに適用しました。Auto-CoT (Zhang et al., 2022b) は、多様な質問をサンプリングし、推論チェーンを生成することによってデモンストレーションを自動構築します。Active-Prompt (Diao et al., 2023)は、タスク固有の注釈に対して最も不確実な質問を選択することに焦点を当てています。PS Prompt (Wang et al., 2023) はタスクをサブタスクに分解します。Tree-of-Thought (ToT) (Yao et al., 2023a) は、推論プロセスを複数の経路として考え、選択肢を自己評価することを特徴としています。Effective Graph-of-Thought (Yao et al., 2023b) は、推論をグラフとして構築します。Natural Program prompting (Ling et al., 2023) は、より良い推論タスクを解決するための手法です。そして、再読プロンプト (Xu et al., 2023b) は、入力プロンプトに埋め込まれた質問情報を再読することで推論を改善します。
4.2 モデルアンサンブル
複数のモデルの強みを活用するための簡単な解決策は、異なるモデルの出力を再ランク付けすることです。例えば、Jiang et al. (2023)は、候補出力をペアで比較し、最適なものを選択するPAIRRANKERを紹介し、自己構築の指示データセットで改善を示しました。マルチLLM推論に関連する大規模な計算コストに対処するために、他の研究では、特定の入力に対して固定されたLLMのセットから最適なモデルを予測するルーターを訓練することが検討されています (Wang et al., 2024a; Shnitzer et al., 2024; Lu et al., 2023)。また、FrugalGPT (Chen et al., 2023b) は、異なるモデルを段階的に使用することでLLMのコストを削減することを提案しました。複数のモデルの応答をより効果的に活用するために、Jiang et al. (2023) は、複数の候補を活用するために改善された応答を生成するように訓練されたGENFUSERというモデルを訓練しました。Huang et al. (2024) は、異なるモデルの出力確率分布を平均化することで、複数のモデルの出力を融合することを提案しました。
別の研究分野として、マルチエージェントの協力が挙げられます。複数の大規模言語モデルをエージェントとして使用し、対話形式で問題を共同で解決する手法がいくつか検討されています。Du et al. (2023) は、エージェント間の対称的な議論メカニズムを確立しました。同時期に、MAD (Liang et al., 2023) は、デベーターとジャッジなどの異なる役割を持つ非対称メカニズムデザインを導入しました。その他の類似研究には、(Chan et al., 2023) が含まれます。さらに、ReConcile (Chen et al., 2023a) は、重み付け投票を含む非対称的な議論の一例です。議論をより深く理解するために、Zhang et al. (2023) は、社会心理学的観点からこのような協力メカニズムを説明することを目的としています。Wang et al. (2024b) は、マルチエージェントアプローチを体系的に比較し、詳細なデモンストレーションを含む強力なプロンプトを使用した単一のエージェントが、マルチエージェントアプローチと同等の応答品質を達成できることを発見しました。
5 結論
この論文では、複数のLLM(大規模言語モデル)の能力を順次的なステージで協力させることで、生成品質を向上させることを目的とした**Mixture-of-Agents(MoA)**アプローチを紹介しました。私たちの手法は、MoAファミリー内のエージェントの集団的な強みを活用し、各個別モデルの出力品質を大幅に改善できることを示しました。AlpacaEval 2.0、MT-Bench、FLASKにおいて行われた実証実験では、私たちのアプローチが最大65%のLC勝率を達成し、応答品質に大幅な改善をもたらしたことが確認されました。これらの結果は、さまざまなモデルの多様な視点を統合することで、単一のモデルに依存するよりも優れたパフォーマンスが得られるという仮説を支持しています。さらに、MoAアーキテクチャの設計を最適化するための洞察を提供し、MoAアプローチの体系的な最適化が今後の研究の興味深い方向性であることを示しています。
制限事項
提案された手法では、モデルの応答を逐次的に集約する必要があるため、最終MoA層に到達するまで最初のトークンを決定することができません。これにより、初回応答までの時間(Time to First Token, TTFT)が長くなり、ユーザーエクスペリエンスに悪影響を及ぼす可能性があります。この問題を軽減するために、MoA層の数を制限することができます。最初の応答の集約が生成品質に最も大きなブーストをもたらすためです。将来的には、応答全体を一度に集約するのではなく、部分的に集約することを検討し、TTFTを短縮しつつ応答品質を維持する方法を探ることが考えられます。
広範な影響
この研究は、LLM駆動のチャットアシスタントの有効性を高め、AIをより身近なものにする可能性を秘めています。さらに、MoAは中間出力が自然言語で表現されるため、モデルの解釈性を向上させる点で重要です。この解釈性の向上は、人間の推論との整合性をよりよく確保するのに役立ちます。
参考文献
- Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al. (2023). Qwen technical report. arXiv preprint arXiv:2309.16609.
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901.
- Chan, C.-M., Chen, W., Su, Y., Yu, J., Xue, W., Zhang, S., Fu, J., and Liu, Z. (2023). Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201.
- Chen, J. C.-Y., Saha, S., and Bansal, M. (2023a). Reconcile: Round-table conference improves reasoning via consensus among diverse llms. arXiv preprint arXiv:2309.13007.
- Chen, L., Zaharia, M., and Zou, J. (2023b). Frugalgpt: How to use large language models while reducing cost and improving performance. arXiv preprint arXiv:2305.05176.
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., et al. (2022). Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Diao, S., Wang, P., Lin, Y., and Zhang, T. (2023). Active prompting with chain-of-thought for large language models. arXiv preprint arXiv:2302.12246.
- Du, Y., Li, S., Torralba, A., Tenenbaum, J. B., and Mordatch, I. (2023). Improving factuality and reasoning in language models through multiagent debate. arXiv preprint arXiv:2305.14325.
- Dubois, Y., Galambosi, B., Liang, P., and Hashimoto, T. B. (2024). Length-controlled alpacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475.
- Fu, Y., Peng, H., Sabharwal, A., Clark, P., and Khot, T. (2022). Complexity-based prompting for multi-step reasoning. arXiv preprint arXiv:2210.00720.
- Guo, D., Zhu, Q., Yang, D., Xie, Z., Dong, K., Zhang, W., Chen, G., Bi, X., Wu, Y., Li, Y., et al. (2024). Deepseek-coder: When the large language model meets programming–the rise of code intelligence. arXiv preprint arXiv:2401.14196.
- Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. (2021). Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874.
- Huang, Y., Feng, X., Li, B., Xiang, Y., Wang, H., Qin, B., and Liu, T. (2024). Enabling ensemble learning for heterogeneous large language models with deep parallel collaboration. arXiv preprint arXiv:2404.12715.
- Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de Las Casas, D., Hanna, E. B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T. L., Gervet, T., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. (2024). Mixtral of experts. CoRR, abs/2401.04088.
- Jiang, D., Ren, X., and Lin, B. Y. (2023). LLM-blender: Ensembling large language models with pairwise ranking and generative fusion. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 14165–14178, Toronto, Canada, July 2023. Association for Computational Linguistics.
- Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. (2022). Large language models are zero-shot reasoners. Advances in Neural Information Processing Systems, 35:22199–22213.
- Liang, T., He, Z., Jiao, W., Wang, X., Wang, Y., Wang, R., Yang, Y., Tu, Z., and Shi, S. (2023). Encouraging divergent thinking in large language models through multi-agent debate. arXiv preprint arXiv:2305.19118.
参考文献 (続き)
- Ling, Z., Fang, Y., Li, X., Huang, Z., Lee, M., Memisevic, R., and Su, H. (2023). Deductive verification of chain-of-thought reasoning. arXiv preprint arXiv:2306.03872.
- Lu, K., Yuan, H., Lin, R., Lin, J., Yuan, Z., Zhou, C., and Zhou, J. (2023). Routing to the expert: Efficient reward-guided ensemble of large language models.
- OpenAI. (2023). GPT-4 technical report.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Papineni, K., Roukos, S., Ward, T., and Zhu, W. (2002). BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA, pp. 311–318. ACL.
- RapidFuzz. (2023). python-levenshtein by rapidfuzz. https://github.com/rapidfuzz/python-Levenshtein.
- Roziere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y., Liu, J., Remez, T., Rapin, J., et al. (2023). Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538.
- Shnitzer, T., Ou, A., Silva, M., Soule, K., Sun, Y., Solomon, J., Thompson, N., and Yurochkin, M. (2024). Large language model routing with benchmark datasets. https://openreview.net/forum?id=LyNsMNNLjY.
- Team, G., Anil, R., Borgeaud, S., Wu, Y., Alayrac, J.-B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A. M., Hauth, A., et al. (2023). Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- The Mosaic Research Team. (2024). Introducing dbrx: A new state-of-the-art open LLM. https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm.
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al. (2023a). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023b). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Wang, H., Polo, F. M., Sun, Y., Kundu, S., Xing, E., and Yurochkin, M. (2024a). Fusing models with complementary expertise. In The Twelfth International Conference on Learning Representations.
- Wang, L., Xu, W., Lan, Y., Hu, Z., Lan, Y., Lee, R. K.-W., and Lim, E.-P. (2023). Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv preprint arXiv:2305.04091.
- Wang, Q., Wang, Z., Su, Y., Tong, H., and Song, Y. (2024b). Rethinking the bounds of LLM reasoning: Are multi-agent discussions the key? arXiv preprint arXiv:2402.18272.
- Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., and Zhou, D. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q. V., Zhou, D., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
図6
補足資料
A スピアマン相関を用いた異なる類似度関数
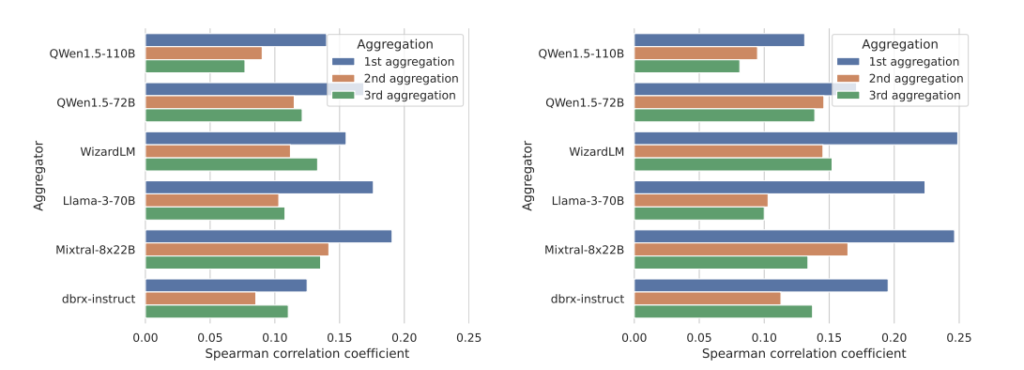
ここでは、スピアマン相関を計算する際に使用されるTF-IDFベースの類似度およびLevenshtein類似度を使用した結果を示します。具体的には、各サンプル内でn個の提案された回答に対して、n個の類似度スコアとGPT-4ベースの評価者によって決定されたn個の好みスコアとの間のスピアマン相関係数を計算しました。図6に示されているように、勝率とTF-IDF類似度およびLevenshtein類似度の間には、正の相関があることが確認されました。
図6: (a) TF-IDF類似度を用いたスピアマン相関 (b) Levenshtein類似度を用いたスピアマン相関
表5: LLMを用いたランク付けのためのプロンプト
pythonコードをコピーするあなたは、高度に効率的なアシスタントであり、指定された指示に対する応答の品質に基づいて、さまざまな大規模言語モデル(LLM)を評価し、最適なものを選択します。このプロセスを通じて、人間の視点で最も正確で好ましい応答を反映したリーダーボードを作成します。
私は、さまざまな大規模言語モデルのリーダーボードが必要です。これらのモデルに与えられたプロンプトと、それに対する対応する出力を提供します。あなたのタスクは、これらの応答を評価し、人間の視点から最適な出力を生成したモデルを選択することです。
## 指示
{
"instruction": """{instruction}""",
}
## モデル出力
ここに、モデルからの順不同の出力があります。各出力は、一意のモデル識別子によって識別される特定のモデルに関連付けられています。
{
{
"model_identifier": "{identifier_1}",
"output": """{output_1}"""
},
{
"model_identifier": "{identifier_2}",
"output": """{output_2}"""
},
{
"model_identifier": "{identifier_3}",
"output": """{output_3}"""
},
{
"model_identifier": "{identifier_4}",
"output": """{output_4}"""
},
{
"model_identifier": "{identifier_5}",
"output": """{output_5}"""
},
{
"model_identifier": "{identifier_6}",
"output": """{output_6}"""
}
}
## タスク
応答の品質と関連性に基づいてモデルを評価し、最良の出力を生成したモデルを選択してください。最良のモデル識別子を提供して応答してください。最良のモデル識別子は次のいずれかでなければなりません(引用符なし、スペースなし、改行なし、...)。
## 最良のモデル識別子
B LLMランカー
このセクションでは、この論文で使用されたLLMランカーの設定を紹介します。LLMランカーは、いくつかのLLMが生成した最適な出力を評価してランク付けするために設計されています。表5には、これらの評価の際に使用されるプロンプトのテンプレートが示されています。このLLMランカーを使用して、提案者が生成した応答の中から最適なものを選び、その最良のランク付け結果をAlpacaEval評価者に評価させました。
表6: 一部のモデルが高品質な応答を生成するケース
| 役割 | 好み度 | 内容 |
|---|---|---|
| ユーザー | – | “Smooth”という曲について話したい。Rob Thomasの曲です。 |
| Qwen1.5-110B-Chat | 0.35 | …これは、SantanaのシグネチャギターとRob Thomasの感情豊かなボーカルを融合させた、ロック、ポップ、ラテン音楽の完璧なブレンドです… |
| Qwen1.5-72B-Chat | 0.00 | … |
| Llama-3-70B-Instruct | 0.00 | …これは、Matchbox TwentyのリードボーカリストであるRob Thomasと伝説的なギタリストSantanaとのコラボレーションです… |
| WizardLM-2-8x22B | 0.99 | …これは米国のBillboard Hot 100チャートで12週間連続でトップに立ちました…この曲の官能的でエネルギッシュな雰囲気を捉えています… |
| Mixtral-8x22B-Instruct-v0.1 | 0.00 | … |
| dbrx-instruc | 0.00 | … |
| Aggregated (Qwen1.5-110B-Chat) | 0.99 | “Smooth”は、Matchbox TwentyのリードシンガーであるRob Thomasと著名なラテンロックギタリストCarlos Santanaのコラボレーションです…この象徴的な曲は、ロック、ポップ、ラテン音楽の要素を融合させ、SantanaのシグネチャギターとRob Thomasの独特なボーカルを披露しています…この曲は、Billboard Hot 100で12週間連続でトップに立ちました…この曲のミュージックビデオは、活気あるクラブシーンを舞台にしており、曲の官能的な雰囲気を引き立てています… |
C ケーススタディ
このセクションでは、ケーススタディを紹介します。すべてのモデルによって生成された応答は非常に長いため、簡潔にするために選択された断片のみを示します。アグリゲーターがどのように応答を統合するかを示すために、提案された応答と統合された応答の間の類似表現を異なる色で下線を引いて示しています。すべての提案された応答に共通する内容は省略しています。
表6では、異なる提案者によって生成された応答が示されています。Qwen1.5-110B-Chatによって生成された統合された応答は、自身の内容への高い好み度を反映しつつ、Llama-3-70B-InstructおよびWizardLM 8x22Bからの重要なポイントも組み込んでいます。特に、GPT-4によるWizardLM 8x22Bの応答に対する好みスコアは0.99であり、最終的な統合応答も0.99の好み度を達成しています。
一方、表7は、提案された応答のどれも高い好みスコアを達成していないケースを示しています。それにもかかわらず、アグリゲーターはこれらの応答から強力なポイントを特定し、組み込み、最終的に0.33の好み度を達成しました。
表7: 提案された応答がどれも高い好みスコアを持たないケース
| 役割 | 好み度 | 内容 |
|---|---|---|
| ユーザー | – | “我々の宇宙は他の宇宙と接触しているのか?” |
| Qwen1.5-110B-Chat | 0.00 | … 我々の宇宙は、多次元宇宙理論に基づいて、他の宇宙と接触する可能性がありますが、このような接触は観測するのが極めて困難です… |
| Qwen1.5-72B-Chat | 0.00 | … 現時点で、我々の宇宙が他の宇宙と接触している証拠はありません… |
| Llama-3-70B-Instruct | 0.16 | … 物理学的な証拠はありませんが、仮説的には可能です… |
| WizardLM-2-8x22B | 0.03 | … 我々の宇宙が他の宇宙と接触しているかどうかについては科学者の間でも意見が分かれていますが、いまだに確固たる証拠はありません… |
| Mixtral-8x22B-Instruct-v0.1 | 0.00 | … 多元宇宙理論によると、無限の宇宙が存在する可能性がありますが、これらが相互作用するかどうかは不明です… |
| dbrx-instruct | 0.00 | … 現在のところ、我々の宇宙が他の宇宙と接触しているという証拠は存在しません… |
| Aggregated (Qwen1.5-110B-Chat) | 0.33 | … 現在の科学的な証拠は、我々の宇宙が他の宇宙と接触していることを支持していませんが、多元宇宙理論に基づくと、この可能性は排除できません… |
D API仕様
D.1 MoAフレームワークのAPI
MoAフレームワークは、API形式で簡単に統合および使用することができます。このAPIは、複数のLLMを統合し、生成された出力の品質を最大化するための一連のエンドポイントを提供します。以下は、APIの主要なエンドポイントの説明です。
- /moa/generate:
- 入力: プロンプト、エージェント設定
- 出力: 統合された最終出力
- 説明: 与えられたプロンプトに基づいて、MoAフレームワークを使用して複数のエージェントが生成する応答を統合し、最終的な出力を返します。
- /moa/evaluate:
- 入力: モデル出力、評価基準
- 出力: 評価スコア
- 説明: 特定のプロンプトに対する異なるモデルの出力を評価し、品質スコアを生成します。
- /moa/rank:
- 入力: モデル出力のセット
- 出力: ランキングリスト
- 説明: 提供されたモデル出力のセットをランク付けし、最適な応答を特定します。
D.2 エンドポイントの使用例
以下は、/moa/generate エンドポイントを使用してプロンプトに応答を生成する簡単な例です。
リクエスト:
bashコードをコピーするPOST /moa/generate
{
"prompt": "ブラックホールの内部では何が起こるのか?",
"agent_config": "default"
}
レスポンス:
jsonコードをコピーする{
"final_output": "ブラックホールの内部は、一般相対性理論によれば無限に小さな一点である特異点を持ちますが、その正確な物理的性質は未解明です。..."
}